Une initiation à l’utilisation de R/RStudio à partir de l’enquête Envie
Claire Kersuzan (PUD-Bx, MSH-Bx/Univ. de Bordeaux, LifeObs/Ined)
Capucine Rauch (PUD-S, MISHA/Univ. de Strasbourg, LifeObs/Ined)
Maude Crouzet (SAGE/Univ. de Strasbourg)
Deuxième partie
Prendre en main les données avec R et RStudio
Explorer, manipuler et produire de premiers résultats statistiques
Comment transformer une base de données d’enquête en résultats interprétables ?
Objectifs
Comprendre :
comment fonctionne l’environnement R/RStudio ;
comment importer et explorer une base de données ;
comment produire de premiers tableaux et graphiques ;
comment manipuler des variables d’enquête ;
pourquoi les traitements réalisés influencent les résultats obtenus (sélection des observations, choix des variables, traitement des données manquantes, indicateur construit , …).
Produire des statistiques ne consiste pas seulement à “faire tourner du code”.
Cela implique toujours une série de décisions méthodologiques.
I. Entrer dans R et RStudio
Dans cette première sous-partie, nous allons voir :
comment fonctionne l’environnement R/RStudio ;
ce qu’est un projet RStudio ;
comment importer les données de l’enquête Envie ;
comment explorer une base de données ;
comment les données sont organisées dans R.
Avant d’analyser des données, il faut comprendre comment elles sont organisées et manipulées dans R.
Pourquoi utiliser R dans cet atelier ?
R est un logiciel :
gratuit et librement accessible ;
largement utilisé dans les environnements professionnels et académiques ;
adapté au traitement et à l’analyse de données d’enquête.
Avec R, on peut notamment :
manipuler des données ;
produire des tableaux ;
créer des graphiques ;
réaliser des analyses statistiques ;
documenter et reproduire ses traitements.
R est ici un outil pour travailler sur des données d’enquête, pas une finalité en soi.
R et RStudio : quelle différence ?
R
moteur de calcul statistique ;
exécute les commandes ;
réalise les traitements.
RStudio
interface de travail ;
facilite l’écriture du code ;
permet d’organiser les fichiers et les résultats.
RStudio permet de travailler plus facilement avec R.
Ouvrir RStudio
Lorsque RStudio s’ouvre, plusieurs zones apparaissent.
On y trouve notamment :
une zone pour écrire du code [2 — Script] ;
une console qui exécute les commandes du script [1 — Console] ;
un espace pour les objets et datasets de l’environnement, l’historique et l’importation des données [3 — Environment] ;
un espace pour les fichiers, les graphiques, les packages et l’aide [4 — Files / Plots / Help].
Activité — Observer l’interface RStudio
Prenez quelques minutes pour repérer :
où on écrit le code ?
où les résultats apparaissent ?
où pourraient apparaître les graphiques ?
où verra-t-on les objets créés pendant la séance ?
Pour faire apparaître la zone Scripts (en haut à gauche): - File → New File → R Script
L’objectif n’est pas de tout comprendre immédiatement, mais de repérer progressivement les principaux espaces de travail.
La console : exécuter des commandes
La console permet :
d’exécuter des commandes ;
d’obtenir des résultats immédiats ;
de tester rapidement du code.
Essayez dans la console :
2+210/5mean(c(2, 4, 6))
Questions
Que renvoie R ?
Que fait mean() ?
Pourquoi utilise-t-on des parenthèses ?
Une commande est exécutée lorsque l’on appuie sur Entrée.
Une logique importante : objets et fonctions
Dans R :
les données sont stockées dans des objets ;
les fonctions permettent d’agir sur ces objets.
Exemple
t <-c(2, 4, 6)mean(t)
[1] 4
c(2, 4, 6) crée une série de valeurs ;
<- est l’opérateur d’assignation (raccourci : Alt + - sous Windows, ⌥ Option + - sous Mac)
t est le nom donné à l’objet créé ;
mean() est une fonction qui calcule une moyenne.
Une grande partie du travail dans R consiste à manipuler des objets avec des fonctions.
Comprendre la structure d’une fonction
Dans R, la plupart des fonctions suivent la même logique :
fonction(objet, argument1 = ..., argument2 = ...)
L’objet peut être une base de données, une variable, un vecteur, un tableau, etc.
Exemple :
head(ENVIE)
On y retrouve :
une fonction : head(), dim() ;
un objet : ENVIE ;
parfois des arguments supplémentaires (obligatoire ou optionnels).
Une fonction réalise une action sur les informations fournies entre parenthèses.
Tous les arguments ne sont pas obligatoires
La plupart des fonctions fonctionnent avec leurs réglages par défaut :
head(ENVIE)
Et acceptent des arguments supplémentaires :
head( ENVIE,n =10)
Ici n = 10 demande à R d’afficher les 10 premières lignes.
Les arguments permettent de modifier le comportement d’une fonction.
Trouver de l’aide dans R
Il n’est pas nécessaire de mémoriser toutes les fonctions.
Pour consulter l’aide d’une fonction :
?head# ouhelp(head)
Une fenêtre d’aide s’ouvre alors dans RStudio. On y trouve notamment :
à quoi sert la fonction ;
les arguments disponibles ;
des exemples d’utilisation.
Savoir chercher de l’aide est souvent plus utile que connaître toutes les fonctions par cœur.
Activité — Explorer l’aide d’une fonction
Essayez :
?sort# ou?max
Questions
Quel est le rôle de la fonction ?
Quels arguments sont proposés ?
Certains arguments semblent-ils optionnels ?
La documentation fait partie intégrante du travail avec R.
R distingue les majuscules et minuscules (Age ≠ age) ;
éviter les noms déjà utilisés dans des fonctions R (mean, table, data, etc.).
Des noms explicites rendent les scripts plus faciles à comprendre et à réutiliser.
Les scripts R
Écrire directement dans la console :
est pratique pour faire des tests ;
mais ne permet pas de conserver son code ou travail.
Les scripts R (fichiers texte) permettent :
d’enregistrer ses commandes ;
de documenter ses traitements ;
de reproduire ses analyses plus tard.
Les scripts permettent de garder une trace des traitements réalisés et de reproduire plus facilement les analyses.
Pourquoi conserver son code ?
Conserver ses scripts permet notamment :
de reproduire ses analyses ;
de corriger des erreurs ;
de modifier facilement un graphique ou un tableau ;
de partager ses traitements ;
de documenter son travail.
Les scripts participent à la reproductibilité des analyses.
Organiser son travail avec un projet RStudio
Lorsque l’on travaille sur des données, on manipule souvent :
des scripts ;
des fichiers de données ;
des graphiques ;
des tableaux ;
de la documentation :
des articles scientifiques.
Un projet permet de regrouper au même endroit tout ce qui concerne une même analyse dans un environnement cohérent.
Pour éviter de perdre des fichiers ou des liens :
il est recommandé de travailler dans un projet RStudio.
Qu’est-ce qu’un projet RStudio ?
Un projet RStudio (.Rproj) correspond à :
un dossier de travail organisé autour d’un fichier .Rproj contenant l’ensemble des éléments liés à une analyse (données, scripts, documentation, etc.).
Exemple d’organisation d’un projet :
Le projet permet à RStudio de savoir où se trouvent vos fichiers.
Pourquoi utiliser un projet ?
Les projets permettent notamment :
d’éviter les erreurs de chemin ;
de partager plus facilement son travail et de reproduire ses analyses sur un autre ordinateur.
Exemple : importer le fichier Envie_fpa.Rdata
# Sans projetload("C:/Users/MonNom/Documents/These/DossierFinalVersion2/data/Envie_fpa.Rdata")# Avec projetload("data/Envie_fpa.Rdata")
Pourquoi est-ce utile ?
- le script fonctionne plus facilement sur un autre ordinateur ;
- les chemins sont plus courts et plus lisibles ;
- toute l’organisation du projet reste au même endroit.
Les projets participent eux aussi à la reproductibilité des analyses.
Ouvrir le projet ENVIE
Pour la suite de l’atelier, nous allons travailler dans le projet RStudio fourni avec le kit.
2. Dans le menu « Projet R à télécharger », téléchargez l’archive Projet_Ex.zip.
3. Décompressez l’archive (clic droit → Extraire tout).
4. Ouvrez le dossier obtenu puis double-cliquez sur :
Envie.Rproj
RStudio s’ouvrira directement dans l’environnement de travail du kit.
Observer le projet ENVIE
Regardez l’onglet Files
→ Repérez les différents dossiers, et observez le nom du projet affiché en haut de la fenêtre.
Vous devriez retrouver les dossiers suivants :
data/ : contient le fichier de données : Envie_FPA.csv ;
doc/ : documentation de l’enquête (questionnaire, dictionnaire des variables, note méthodologique du FPA ; article dont certains résultats seront reproduits ;
scripts/ : les scripts de correction des exercices ; vos futurs scripts d’analyse ;
resultats/ : tableaux, graphiques, exports et résultats produits.
Question
Pourquoi est-il utile que tout le monde travaille dans la même organisation de fichiers ?
Cela facilite le partage des scripts, la reproduction des analyses et le repérage des fichiers.
Créer son premier script
Création d’un script qui servira tout au long de l’atelier.
Étape 1
Créer un nouveau script :
File → New File → R Script
Étape 2
Enregistrer le script :
File → Save
enregistrer le fichier dans le dossier : scripts/ du projet
sous le nom : Script_Envie_Ete.R
Exécuter une commande dans un script
Écrivons une première commande dans notre script :
2+2
Pour exécuter une commande :
placer le curseur sur la ligne puis cliquer sur
sélectionner une ou plusieurs lignes puis cliquer sur
utiliser le raccourci clavier : Windows / Linux : Ctrl + Entrée ou Mac : Cmd + Entrée
Questions
Où apparaît le résultat ?
Quelle est la différence entre le script et la console ?
Le script permet d’écrire et de conserver les commandes
La console permet de les exécuter et d’afficher les résultats.
Penser à sauvegarder régulièrement son script
Lorsque vous modifiez un script :
les changements ne sont pas enregistrés automatiquement.
Pour sauvegarder :
menu File → Save ;
ou raccourci clavier :
Windows / Linux : Ctrl + S
Mac : Cmd + S
Pourquoi est-ce important ?
éviter de perdre son travail ;
pouvoir reprendre facilement plus tard.
Sauvegarder régulièrement fait partie des bonnes pratiques de travail avec R.
Les erreurs font partie du travail
Qui pense qu’il va faire une erreur de code aujourd’hui ?
Tout le monde.
Lorsque R affiche un message d’erreur :
ce n’est pas forcément grave ;
cela indique souvent ce qui pose problème ;
il faut essayer de le lire avant de modifier le code.
Erreurs fréquentes
objet introuvable ;
parenthèse oubliée ;
faute de frappe ;
package non chargé.
Même les utilisateurs expérimentés rencontrent régulièrement des erreurs.
car certaines analyses nécessitent parfois de changer le type d’un objet ou d’une variable.
Explorer et décrire les données
Dans cette sous-partie, nous allons apprendre à :
explorer une variable ;
produire des tableaux simples ;
repérer les valeurs manquantes ;
réaliser quelques premiers graphiques ;
comprendre ce que décrivent réellement les résultats.
Avant de tester des hypothèses, il faut d’abord connaître ses données.
Une première question sur les données
Une fois les données importées :
que regardez-vous en premier dans une base de données ?
Quelques possibilités :
quelles variables sont disponibles ?
combien de personnes ont été interrogées ?
existe-t-il des valeurs manquantes ?
certaines catégories sont-elles rares ?
quelles répartitions des réponses observe-t-on ?
Avant toute analyse, il est important de comprendre ce que mesurent les variables et comment les réponses se répartissent.
Cette étape est appelée : exploration des données
Toutes les variables ne contiennent pas le même type d’information
Variable
Ce qu’elle mesure
Type
Exemple de résumé
sadr_rec
Usage d’un site ou d’une application de rencontre
Qualitative
Effectifs, pourcentages
genre_id
Genre déclaré
Qualitative
Effectifs, pourcentages
par_men_5
Origine sociale du ménage parental
Qualitative
Répartition par catégorie
poids_rec
Poids déclaré (kg)
Quantitative
Moyenne, médiane
Le type de variable influence les tableaux, les graphiques et les analyses possibles.
Activité — Que va afficher cette commande ?
table(ENVIE$sadr_rec)
Questions
Que fait la fonction table() ?
Que représentent les nombres affichés ?
S’agit-il d’effectifs ou de pourcentages ?
Compter les réponses
La fonction table() compte le nombre de personnes dans chaque catégorie.
table(ENVIE$sadr_rec)
1 2
5925 4087
Ce tableau présente des effectifs, c’est-à-dire un nombre de personnes.
Les effectifs suffisent-ils ?
Nous savons que :
5925 personnes déclarent un usage ;
4087 déclarent un non-usage.
Question
5925 personnes :
est-ce beaucoup ou peu ?
Pour répondre, il faut aussi connaître :
la taille totale de l’échantillon ;
la proportion représentée par chaque catégorie.
Les pourcentages sont souvent plus faciles à interpréter que les effectifs.
Calculer des pourcentages
Pour obtenir directement les effectifs et les pourcentages :
freq(ENVIE$sadr_rec)
n % val%
1 5925 59.1 59.2
2 4087 40.8 40.8
NA 9 0.1 NA
Cette fonction du package questionr affiche notamment :
les effectifs et les pourcentages ;
les valeurs manquantes.
Question
Pourquoi les pourcentages facilitent-ils les comparaisons ?
Ils permettent de comparer des groupes même lorsque leurs effectifs diffèrent.
Les valeurs manquantes sont-elles nombreuses ?
Essayons maintenant :
table( ENVIE$sadr_rec,useNA ="ifany")
L’option useNA = "ifany" demande à R :
d’afficher également les valeurs manquantes (NA) s’il y en a.
Questions
Combien de NA apparaissent ?
Leur nombre vous semble-t-il important ?
Faut-il toujours les ignorer ?
Une première lecture des résultats
Pour la variable sadr_rec :
5925 personnes déclarent un usage (modalité 1) ;
4087 déclarent un non-usage (modalité 2);
9 observations sont manquantes (modalité NA).
Les valeurs manquantes sont ici très peu nombreuses.
Mais attention
Dans d’autres variables :
les NA peuvent être beaucoup plus nombreux ;
ils peuvent résulter de filtres du questionnaire ;
ils peuvent correspondre à des non-réponses ;
ils peuvent influencer l’interprétation des résultats.
Vérifier les valeurs manquantes fait partie de l’exploration des données.
Que faire lorsqu’il y a beaucoup de valeurs manquantes ?
Les valeurs manquantes peuvent :
être décrites ;
être exclues de l’analyse ;
être regroupées dans une catégorie spécifique ;
être remplacées par des méthodes adaptées.
Il n’existe pas de solution universelle.
Avant toute décision, il faut comprendre pourquoi les données sont manquantes.
Certaines modalités peuvent être rares
Pour certaines variables :
certaines catégories regroupent très peu de personnes ;
certaines réponses sont très peu fréquentes.
Cela peut poser plusieurs problèmes :
résultats instables ;
comparaisons fragiles ;
difficultés d’interprétation.
Avant d’analyser une variable, il est important de regarder les effectifs de chaque modalité.
Que faire des modalités rares ?
Lorsqu’une modalité est très peu représentée, plusieurs choix sont possibles :
la conserver ;
la regrouper avec d’autres catégories ;
ou signaler explicitement la fragilité des résultats.
Mais attention un regroupement doit toujours avoir :
un sens du point de vue de l’analyse ;
une cohérence avec la question étudiée ;
et être interprétable sociologiquement.
Question
Regrouper des catégories est-il un choix uniquement “technique” ?
Les regroupements sont des choix méthodologiques et d’interprétation.
Il modifie la façon de décrire la réalité
Représenter une variable avec un graphique
Les tableaux permettent de résumer les données.
Les graphiques permettent souvent de :
repérer rapidement les écarts ;
comparer les catégories ;
communiquer les résultats.
Pour une variable qualitative comme sadr_rec :
le graphique le plus courant est le diagramme en barres.
Premier graphique
Essayons :
barplot(table(ENVIE$sadr_rec))
Questions
Que représente chaque barre ?
Que représente sa hauteur ?
Quelle catégorie est la plus fréquente ?
Ce graphique est volontairement très simple : il permet surtout d’explorer rapidement les données.
Un graphique ne remplace pas l’analyse, mais il aide à visualiser les données.
Dans la suite de l’atelier, nous verrons comment produire des graphiques plus lisibles et personnalisés
Toutes les variables ne se résument pas de la même manière
Les variables qualitatives décrivent :
des catégories ;
des groupes ;
des modalités.
Les variables quantitatives décrivent :
une quantité ;
une mesure ;
une valeur numérique.
Exemple de variable quantitative dans Envie :
poids_rec
le poids déclaré des enquêté·es.
Résumer une variable quantitative
Essayez cette commande :
summary(ENVIE$poids_rec)
Cette fonction fournit notamment :
le minimum et le maximum ;
la médiane ;
les quartiles ;
la moyenne.
Question
Pourquoi ne peut-on pas utiliser un simple tableau d’effectifs comme pour sadr_rec ?
Parce que poids_rec peut prendre un très grand nombre de valeurs différentes : 52, 53, 54, etc.
Il est souvent plus utile de résumer une variable quantitative à l’aide d’indicateurs statistiques.
Lire un résumé statistique
Pour poids_rec, on obtient :
Indicateur
Valeur
Minimum
35
Médiane
68
Moyenne
69,5
Maximum
184
Questions
La moyenne et la médiane sont-elles identiques ?
Pourquoi peuvent-elles différer ?
La moyenne est légèrement supérieure à la médiane. Cela peut s’expliquer par la présence de quelques poids très élevés qui “tirent” la moyenne vers le haut.
La médiane correspond à la valeur qui partage l’échantillon en deux groupes de même taille.
La moyenne correspond à la somme des valeurs divisée par le nombre d’observations.
La moyenne est généralement plus sensible aux valeurs extrêmes que la médiane.
Visualiser une variable quantitative
Pour comprendre une variable quantitative, on peut aussi regarder sa distribution.
Deux graphiques simples sont utiles :
l’histogramme ;
la boîte à moustaches.
Les graphiques permettent souvent de voir plus rapidement ce qu’un tableau de nombres résume difficilement.
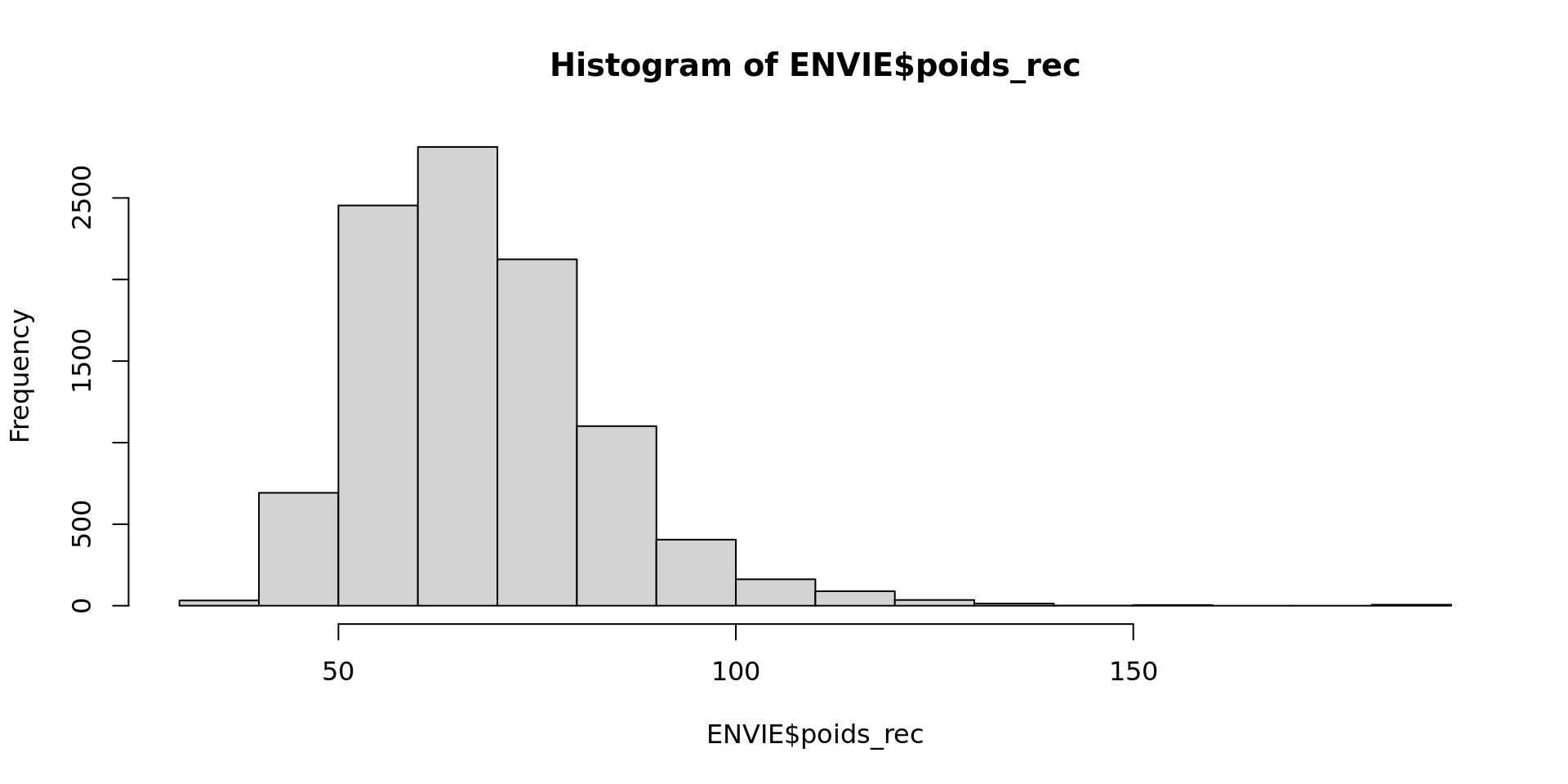
Histogramme : voir la distribution
Essayez :
hist(ENVIE$poids_rec)
Ce graphique permet d’explorer rapidement la répartition des valeurs dans l’échantillon.
Questions
Où se concentrent les valeurs ?
Observe-t-on une ou plusieurs zones où les valeurs sont fréquentes ?
Les poids les plus élevés sont-ils nombreux ou rares ?
Comment lire une boîte à moustaches ?
Avant de l’interpréter, il faut comprendre ce que représentent ses différents éléments.
le trait au centre correspond à la médiane ;
la boîte contient les 50 % d’observations les plus centrales ;
les moustaches indiquent jusqu’où s’étendent la plupart des observations ;
les points isolés correspondent à des observations éloignées du reste des données.
Questions
Où se situe la médiane ?
Les valeurs sont-elles très dispersées ?
Y a-t-il des points isolés ?
Une boîte à moustaches permet de visualiser rapidement le centre, la dispersion et les éventuelles valeurs atypiques.
Vers les tableaux croisés
Décrire une variable est utile.
Mais une question de recherche porte souvent sur :
la relation entre deux variables.
Par exemple
les usages des applications de rencontre diffèrent-ils selon le sexe ?
la vie en couple varie-t-elle selon l’origine sociale ?
certaines situations sont-elles plus fréquentes dans certains groupes ?
Pour répondre à ces questions :
nous allons apprendre à construire des tableaux croisés.
Préparer les données avant de croiser
Avant de produire un tableau ou un graphique, il faut souvent :
sélectionner les variables utiles ;
filtrer certaines observations ;
créer ou recoder des variables ;
vérifier les valeurs manquantes ;
appliquer éventuellement une pondération.
Ces opérations seront centrales dans la reproduction.
On ne produit pas un résultat statistique directement à partir d’un fichier brut.
Les fonctions que nous allons utiliser
Dans la suite, nous allons rencontrer quelques fonctions importantes :
Fonction
Rôle
select()
sélectionner des variables
filter()
sélectionner des individus
mutate()
créer ou modifier une variable
table()
compter des effectifs
wtd.table()
produire un tableau pondéré
Ces fonctions serviront directement dans l’exercice de reproduction des résultats d’un article scientifique.
Une idée importante : le pipe |>
Dans R, on peut enchaîner plusieurs opérations avec le pipe noté |>
Il se lit comme : « puis »
Raccourci RStudio :
Windows / Linux : Ctrl + Maj + M
Mac : Cmd + Maj + M
Exemple
ENVIE |>select(sadr_rec)
On peut lire ce code comme :
prendre l’objet ENVIE, puis sélectionner la variable sadr_rec.
Le pipe permet d’écrire des traitements étape par étape, de manière plus lisible.
Sélectionner des variables avec select()
Les bases de données contiennent souvent :
beaucoup de variables ;
dont seule une partie est utile pour une analyse donnée.
La fonction select() permet de :
conserver uniquement certaines variables.
ENVIE |>select( sexid_rec, sadr_rec )
Activité — Que va produire cette commande ?
ENVIE |>select( age_rec, couple12M, par_men_5 )
Questions
Combien de colonnes restera-t-il ?
Le nombre d’individus change-t-il ?
Pourquoi cette étape peut-elle être utile ?
select() agit sur les colonnes, pas sur les individus.
Quelques symboles utiles dans R
Dans les commandes R, certains symboles reviennent souvent :
Symbole
Signification
<-
créer un objet
==
est égal à
!=
différent de
>=
supérieur ou égal
<=
inférieur ou égal
|>
puis
Activité - Que font ces commandes ?
age30 <- age_rec >=30
→ créer une variable indiquant si l’âge est supérieur ou égal à 30 ans (age30 est une variable logique TRUE / FALSE).
sadr_rec ==1
→ vérifier si sadr_rec vaut 1.
Ces symboles servent à construire des conditions et des traitements sur les données.
Filtrer des individus avec filter()
Parfois, une analyse ne concerne qu’une partie de l’échantillon.
La fonction filter() permet :
de conserver uniquement certains individus (lignes).
ENVIE |>filter( age_rec >=25 )
Activité — Interpréter un filtre
Que conserve cette commande ?
ENVIE |>filter( sadr_rec ==1 )
Questions
Quels individus restent dans la base ?
Le nombre de colonnes change-t-il ?
Que devient le reste des individus ?
filter() agit sur les lignes, pas sur les variables.
Créer une variable avec mutate()
Il est fréquent de :
recoder une variable ;
créer une nouvelle catégorie ;
construire un indicateur.
La fonction mutate() permet :
d’ajouter une nouvelle variable.
ENVIE |>mutate(age30 = age_rec >=30 )
Combiner plusieurs conditions
Dans certaines analyses, on souhaite sélectionner :
plusieurs conditions en même temps ;
ou plusieurs situations/modalités possibles.
Symbole
Signification
&
ET
|
OU
%in%
appartient à plusieurs valeurs
is.na()
valeur manquante
!is.na()
valeur non manquante
Exemples de combinaison de conditions
ENVIE |>filter( age_rec >=25& couple12M ==1 )
conserver les personnes âgées de 25 ans ou plus ; ET ayant été en couple dans les 12 derniers mois.
ENVIE |>filter( genre_id ==2| genre_id ==3 )
conserver les femmes ; OU les personnes non-binaires.
Activité — Comment lire ces conditions ?
Que font les commandes suivantes ?
# Exemple 1ENVIE |>filter(age_rec <25)# Exemple 2ENVIE |>filter( couple12M ==1& sadr_rec ==1 )# Exemple 3ENVIE |>filter( genre_id %in%c(2,3) )
Les analyses sont souvent une succession de petites opérations simples.
Vers les tableaux croisés
Nous savons maintenant :
sélectionner des variables ;
filtrer des individus ;
créer des variables.
Nous pouvons donc répondre à des questions comme :
L’usage des applications de rencontre varie-t-il selon le sexe ?
Pour cela :
nous allons croiser deux variables.
Construire un tableau croisé
Essayez :
table( ENVIE$sexid_rec, ENVIE$sadr_rec)
Questions
Que représentent les lignes ?
Que représentent les colonnes ?
Que représentent les nombres affichés ?
Lire un tableau croisé
Un tableau croisé permet de voir :
comment se répartit une variable selon les modalités d’une autre.
Mais les effectifs seuls sont souvent difficiles à comparer.
Question
Pourquoi est-il difficile de comparer directement deux groupes de tailles différentes ?
Les effectifs dépendent de la taille des groupes.
Passer aux pourcentages
Pour comparer les groupes, on utilise souvent des pourcentages.
Avec le package questionr, on peut calculer des pourcentages en ligne :
table( ENVIE$sexid_rec, ENVIE$sadr_rec) |>lprop()
1 2 Total
1 64.6 35.4 100.0
2 53.1 46.9 100.0
All 59.2 40.8 100.0
Ici chaque ligne totalise 100 %.
Nous allons maintenant apprendre à interpréter ces pourcentages.
Que signifie « pourcentage en ligne » ?
Avec lprop(), on lit les pourcentages ligne par ligne.
Dans notre exemple, cela permet de répondre à la question :
parmi les hommes, quelle proportion utilise une application ?
parmi les femmes, quelle proportion utilise une application ?
On compare donc l’usage des applications à l’intérieur de chaque groupe.
Et les pourcentages en colonne ?
Avec questionr, on peut aussi calculer des pourcentages en colonne :
table( ENVIE$sexid_rec, ENVIE$sadr_rec) |>cprop()
Ici chaque colonne totalise 100 %.
La question devient alors :
parmi les personnes qui utilisent une application, quelle proportion d’hommes et de femmes observe-t-on ?
Ligne ou colonne : attention au dénominateur
Le même tableau peut être lu de deux manières différentes.
lprop()
Pourcentages en ligne
Parmi les hommes/femmes, quelle proportion utilise une application ?
cprop()
Pourcentages en colonne
Parmi les utilisateur·ices, quelle proportion d’hommes et de femmes ?
Un pourcentage n’a de sens que si l’on sait par rapport à quoi il est calculé.
Activité — Interpréter un tableau croisé
À partir du tableau suivant :
table( ENVIE$sexid_rec, ENVIE$infmer) |>lprop()
Questions
Quels pourcentages sont calculés ?
Que représentent les lignes ? les colonnes ?
Comment interpréter ces pourcentages ?
Observe-t-on des différences entre groupes ?
Ces différences semblent-elles importantes ?
lprop() calcule ici des pourcentages en ligne.
les lignes correspondent aux groupes (sexid_rec) ; les colonnes correspondent aux modalités de infmer.
→ On compare donc la répartition des réponses à l’intérieur de chaque groupe.
Un tableau croisé permet d’observer des écarts entre groupes.
Mais il ne permet pas, à lui seul :
de conclure à une association statistique ;
ni d’établir une relation de cause à effet.
Observer une différence ne signifie pas encore l’expliquer.
Les pondérations dans une enquête
Dans une enquête :
certaines personnes répondent davantage ;
certains groupes sont plus difficiles à contacter ;
l’échantillon obtenu peut différer légèrement de la population étudiée.
Pour limiter ces déséquilibres, on utilise souvent une variable de pondération.
Dans Envie, cette variable s’appelle : poidscal
Elle permet notamment :
de rapprocher l’échantillon de certaines caractéristiques de la population ;
de corriger partiellement certains déséquilibres ;
de mieux représenter certains groupes.
Toutes les personnes interrogées ne « pèsent » donc pas exactement le même poids dans l’analyse.
Un tableau non pondéré
Jusqu’à présent, nos tableaux étaient :
non pondérés.
Autrement dit :
chaque personne comptait exactement de la même manière dans les calculs.
Question
Pourquoi cela peut-il poser problème dans certaines analyses ?
Certains groupes peuvent être sur- ou sous-représentés dans l’échantillon.
Produire un tableau pondéré
Avec wtd.table() du packagequestionr, on peut produire un tableau pondéré :
Ici weights = ENVIE$poidscal indique à R : quelle variable de pondération utiliser.
Attention
Les effectifs obtenus sont ici beaucoup plus élevés que le nombre de personnes réellement interrogées dans l’enquête. Pourquoi ?
Parce que le tableau pondéré ne décrit plus seulement l’échantillon, mais cherche à représenter l’ensemble des jeunes de 18–29 ans vivant en France hexagonale.
Pondéré ou non pondéré ?
Lors des premières explorations des données, on travaille souvent sans pondération pour :
examiner l’échantillon ;
repérer des valeurs atypiques ;
observer les distributions ;
identifier des données manquantes.
En revanche, pour produire des résultats décrivant une population :
la pondération devient souvent importante.
Questions
Pourquoi les résultats pondérés peuvent-ils changer ?
Dans quels cas la pondération devient-elle essentielle ?
Les choix méthodologiques influencent les résultats produits.
Visualiser les données avec ggplot2
Les tableaux permettent de résumer les données.
Les graphiques permettent souvent de :
comparer rapidement des groupes ;
repérer des écarts ;
communiquer plus facilement les résultats.
Dans R, le package le plus utilisé pour produire des graphiques est ggplot2
ggplot2 permet de construire des graphiques esthétiques de manière très flexible.
Construire un graphique plus facilement avec esquisse
Le package esquisse propose une interface graphique pour construire des visualisations avec ggplot2.
Il permet notamment :
de sélectionner des variables ;
tester différents graphiques ;
modifier rapidement la représentation ;
générer automatiquement le code R correspondant.
Dans la partie suivante, nous utiliserons esquissepour reproduire un graphique tiré d’une publication scientifique
Les graphiques sont eux aussi le résultat de choix méthodologiques et de représentation.
Pour aller plus loin : produire des tableaux publiables
Dans cet atelier, nous utilisons surtout : table(), freq(), lprop(), cprop().
Mais d’autres packages permettent de produire :
des tableaux plus lisibles et directement utilisables dans un mémoire ou un article.
Quelques exemples : gtsummary, sjPlot, gt
Ces packages permettent notamment :
d’améliorer la mise en forme ;
d’ajouter automatiquement des pourcentages ;
d’exporter des tableaux vers Word ou HTML.
Conclusion de cette partie
Dans cette partie, nous avons appris à :
importer un fichier de données ;
explorer une base dans R ;
produire des tableaux simples ;
calculer des pourcentages ;
construire des tableaux croisés ;
utiliser une pondération ;
préparer des données pour l’analyse.
Les résultats statistiques ne “sortent” jamais directement d’un fichier : ils dépendent toujours de choix d’analyse et de traitement des données.
Vers la reproduction d’un résultat scientifique
Dans la section suivante, nous allons mettre en pratique les notions abordées précédemment :
exploration des variables ;
traitement des données manquantes ;
tableaux croisés ;
pourcentages ;
pondération ;
visualisation des résultats.
Pour reproduire la figure :
« Avoir été en couple dans l’année selon l’âge et l’origine sociale »
tirée de l’article de Bergström M., Maillochon F. et l’équipe Envie, publié en 2024 dans Population & Sociétés :
« Couples, histoires d’un soir, “sexfriends” : diversité des relations intimes des moins de 30 ans »





Comment lire une boîte à moustaches ?
Avant de l’interpréter, il faut comprendre ce que représentent ses différents éléments.
Questions